Writing Components for Pentaho Dashboard Designer 3.8.0
 Comments(0)
Comments(0) Beginning in Pentaho BI Suite 3.8.0, it is now possible to extend Pentaho’s Enterprise Dashboard Designer by adding custom embedded widgets to the UI. For a while now, it has been possible to include content from the repository as dashboard widgets. If you are writing a Pentaho BI Server plugin, modify the settings.xml to include the following xml:
<dashboard-widgets>
<mytype>scripts/widget/MyWidget.js</mytype>
</dashboard-widgets>
This js file should contain your CDF Component implementation, a static method on the component called newInstance() for initial construction of the dashboard widget, along with a call to the dashboard designer to register the component:
PentahoDashboardController.registerComponentForFileType("mytype", MyComponent);
See Analyzer’s plugin.xml and AnalyzerDashboardWidget.js for an example of the implementation.
Starting with the 3.8.0 release, it is easy to add your own embedded content into Dashboard Designer as well. The three available embedded widget types, Chart, Data Table, and URL, have been converted over to plugins, so it’s easy to see how this can be done.
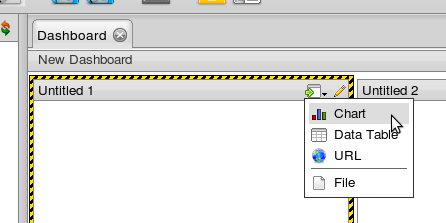
First, in a similar manner to repository content, you need to implement a CDF Component. In addition to the basic component implementation, you also need to provide the following javascript attributes and methods to your component:
Attributes
iconImgSrc - The location of the icon image to appear in the new widget drop down list and editor panel.
localizedName - The name of the widget that will appear in the new widget drop down list and editor panel.
Methods
createWidget() - This method is called when a user selects the widget from the new widget drop down list as seen in the image above. This method should present the user with a UI for creating a new widget, and then create the widget, wiring it up to the dashboard after creation.
editWidget() - This method is called when a user clicks the edit icon within the widget panel. This method does practically the same thing as the createWidget(), but also has access to the currentWidget javascript object that contains a pointer to the widget being edited.
Once you’ve defined the component you also need to register the widget type with the dashboard. Make this call at the end of your javascript file:
PentahoDashboardController.registerWidgetType(new MyEmbeddedComponent());
Finally, register this javascript file the same way as we did above within your settings.xml file.
With just a few lines of javascript, you can create your own component for Pentaho Dashboard Designer!
